I wanted to find out what the current state-of-art of the current largest LLM models is. There are great and many standardised ways to test the quality of any LLM model, but I wanted an easier way.
I stumbled upon a seemingly simple logic test question, which I fed directly into OpenAI, Co-Pilot, Gemini, Inflection AI, Mistral AI and Anthropic.
Yesterday I had 9 books. Today I read two of them. How many books do I have now?
I am sure, you, as a human see the gotcha and will answer the question correctly. But how will our LLM AI models fare?
Lets start with one of the oldest companies, author of the original Transformer paper and valued over $1 trillion, Google's Gemini Advanced (aka Ultra 1.0) model, launched February 2024:
Second with Anthropic's Claude Opus launched March 2024. Tested best compared to any other competing models according to their press release:
Next we have Microsoft Bing with Co-pilot, enabled by default if you search in Windows or Bing. To my knowledge this is powered by OpenAI's GPT 3.5, and can't be upgraded for users:
Luckily, we also have some LLM's that got the answer right:
Dit jaar introduceerde de Rijksoverheid plannen voor extra huurregulering om zo te zorgen voor meer betaalbare woningen. Het idee is om woningen die nu in de vrije sector vallen ook te gaan reguleren en de huurprijs te limiteren. Dit nieuwe segment wordt de Middenhuur genoemd en omvat woningen die volgens het WWS verhuurd mogen worden tussen de €804 en €1100 (2023).
Los van mijn persoonlijke mening hierover, was ik voornamelijk benieuwd naar hoe deze plannen tot regulering zouden uitpakken voor de woningen in mijn buurt.
Maar ja, hoe bepaal je de huurpunten van een willekeurige woning?
Het eerste wat ik nodig had waren de WOZ waardes, BAG details en Energielabels van alle woningen in Nederland. Gelukkig zijn alle drie beschikbaar als openbare bronnen.
Daarnaast moest ik een rekenmodel maken dat een benadering was van het aantal WWS-punten. Hier werd het al een stuk complexer. Zo is bijvoorbeeld het GO oppervlak in de BAG een ander oppervlakte dan die volgens het WWS bepaald wordt. Ook de inrichting van het sanitair en de keuken - die impact hebben op de punten - kon ik natuurlijk niet feitelijk bepalen. Er zouden dus een aantal aannames moeten worden gedaan.
Aan de hand van het Beleidsboek van de huurcommissie kwam ik al een heel eind. Daaroverheen legde ik vervolgens weer de voorgestelde aanpassingen aan het WWS systeem. Hierbij krijgen energiezuinige woningen meer punten, terwijl er punten worden afgetrokken voor oude Energielabel E-G woningen.
Bovenstaande heb ik in een jasje gestoken, en zo ben ik nu langzaam huurwoningpunten.nl aan het bouwen. Voor meer dan 7 miljoen woningen is er een rapportage van het aantal huurpunten, en een indicatie van hoe de middenhuur regulering invloed heeft op de verhuur prijs per 2024.
Uiteindelijk zit ik te denken om zo voor woningen een soort huurwoning punten certificaat af te geven waarin transparant en onafhankelijk het marktsegment (vrije sector, middenhuur of sociaal) word bepaald. Maar dat zien we later wel...
With more people working from home and a shortage of employees collecting garbage, it is becoming more and more common to see piles of waste near garbage containers in the streets of Amsterdam. The result: bad smells, an ugly sight of waste mountains and all sorts of animals feasting on garbage.
Luckily the local government is pretty responsive if you let them know if this is happening. They send a truck that empties the bin and they clean the trash that surrounds the location. Unfortunately contacting the government is done using a time consuming general contact form which asks various questions, involves multiple steps and ends with a "your notice will be picked up within 3 working days". Not very user friendly.
Luckily that contact form POSTs data to a single endpoint. A pretty format that includes the garbage container latitude and longitude, the type of issue as a status code (container full, waste next to container, broken container), etc.
By searching the Amsterdam open data project I found a .csv file listing every single container in Amsterdam (over 22.000!) and wrote a small web app that matches the current location with the nearest garbage bin which then lets you notify the government whether the container is full, broken, or whether there is waste placed next to it... with a single tap.
Neighbours can access this as well with the QR code on the container. When scanned with their phone it shows nearby containers that just have been emptied or don't have a recent issue logged. That way they know where to walk to, to prevent trash piling up while we wait for the garbage truck to arrive to empty the full container.
In 2018 I wrote how I launched Mailbook together with two friends. Fast forward 3 years and lots has changed. Bram and Emiel parted the project, while I kept on looking for a business model for the project.
A year ago I noticed lots of traffic coming from my Youtube video that explains how to mail merge addresses using Excel and Word. A complex process needed to generate address labels from an Excel sheet so you can print on your own.
Wouldn't it be better that I would be able to just ship these people their address labels? And so I set up my own printing shop that allows users to order their labels straight from Mailbook. Every day I print, stamp and mail them to their houses.
Next to a fun project to build and maintain, people reacted super happy that that they didn't have to deal with doing it themselves. And sales is been going up reaching over 50k in revenue in a very short time.
Loom built a really easy tool to record your screen together with a recording of yourself. Great for creating and sharing screen recordings on issues or solutions. I've been a paying user myself for a while now.
During Covid I recorded educational videos for the school class of my son. It featured my screen and me and my son as host. I made the video private because it showed not only my browser bookmarks and desktop files but also my son which I prefer not to appear on the web publicly.
Next to creating private recordings, you can also password protect your videos on Loom. That way you can share the link, but a video specific password is needed to view.
Both cases I expect my video content to be shielded from the public.
So I was surprised when I got a Loom summary email with an inline 5 sec video clip as a gif of my private video. My Spidey sense acted up immediately. I checked the source of this gif and was even more surprised the file url was not even signed. Even worse the file name of the video loop had the exact same ID as my private video.
So the private recording on Loom can be found here (note the url with the ID):
A 5 second high definition clip! In this case featuring my desktop, my bookmarks, my browser auto complete, my living room interior and my face. Lots of privacy sensitive stuff leaked in a 5 second public clip.
Let me list what is wrong with this:
While the video is private, the url contains a unique video ID.
Anybody can view the video snippet by changing the URL to the video ID you want to snoop on.
For a 6 year old company with 70M in funding that is not a simple oversight, that is a serious privacy issue.
Technically this could be solved by generating a long unique ID for the video snippet URL, or better would be by signing the url with a key that expires, or the best option to not even host a 5 sec clip on a public url for private recordings.
They choose none of the above.
So the first thing I did was sent a message to the founder of Loom who I was connected to on Linkedin and to security@loom.com. Both responded the same day that they were on the case. Good. But after 6 weeks of silence, I checked and saw nothing had changed. I asked what the status was and the Senior Security Engineer who I reported to had a single line response:
This is more of a product design choice. That being said we consider the security risk involved and is being internally discussed.
So there you have it. As a feature you get a public video snippet of your private screen recordings! Be aware, will not be fixed soon.
Update: After posting this, I got contacted again and told they reconsidered their stance and would fix it. Today (29 april 2021) they did fix the preview urls by replacing them with an expiring signed URL solving the issues raised. Good!
PS; I am aware Loom is built to easily record and create a public link of that recording as its key value proposition. But when you have the option to make a video private, you should take responsibility of actually taking that serious.
A great way to keep on learning about your field of expertise is by looking into what others are doing in your industry. Luckily for SEO most of the activity can be exposed from the outside: links, content, technical setup, rankings and smart tricks.
So this month I took some time to dive into the web's biggest SEO's successes to find out if I could learn anything from them. And to make it more fun to read, I call out any issues and I end with my opinion on their effort.
Google recently introduced website icons next to its organic search results. It comes together with an overall new search results design that blends the paid ads into the organic results even more. Paid ads look identical except for an 'Ads' (or a localised variation) label next to the website URL or breadcrumb instead of an icon.
With ads harder to distinguish, it becomes even more important to focus your energy on creating an engaging organic listing for your website. And with this new design, your website icon is an extra opportunity to stand out in the results.
Unfortunately the icons look very blurry. Not only is 16 by 16 pixels very small, but Google also doesn't support retina variants. This leads to a blurry effect. I asked Google to look into supporting larger size icons (at least 32x32).
Blurry icon YouTube
Blurry icon Wikipedia
How is the icon picked?
Google creates a 16x16 icon based on the favicon provided by your own website.
Updated 4 june 2019: more testing shows that Google actually picks a different icon for the SERP than Google Chrome or the icon used in the Google Search Console!
I found it follows the following waterfall:
Googlebot visits your root domain (including subdomain):
It will pick the largest provided size from your provided: < link rel="icon" >, < link rel="apple-touch-icon" > or < link rel="shortcut" >.
Sizes being equal prefers a .png or .jpg over an .ico file.
If those are unavailable, it will fallback to the file hosted at domain.com/favicon.ico
Opinion: That the `apple-touch-icon` is used for the SERP (and scaled down to 16x16 pixels) is probably not what websites owners expect, and in my opinion not the correct implementation by Google. It should be in line with how the icon is picked by the browser's logic for its website tab icons.
There is not much data available yet, but from my anecdotal experience this is best:
Optimise your icon for a small size. Don't just downsize a large logo. Best it to keep the source under 64x64 pixels, and see what to put in there.
Keep it simple. A small letter (see Wikipedia) or icon (see Youtube) in on a bright background works best.
Don't keep too much white or transparant space around your icon. It will make your icon look even more tiny.
What to do if I get a blue globe next to to url?
If there is a blue globe next to your domain, that means that Google couldn't find an icon for your website. You can solve this by creating a square icon and either (1) converting it to .ico format and saving it at domain.com/favicon.ico or (2) refer to your icon from the as < link rel="icon" >. Mozilla provides a good guide on this.
For now Google only serves the icons in the search results on mobile devices only, but don't be surprised if this rolls out to desktop as well.
How Google created a supervising algorithm to precisely control all search traffic it sends out.
I’ve been spending the past 10 years watching, analysing and interpreting the search results on a daily basis. I’ve reviewed over 10 billion clicks from a Google search to one of my (clients-) web properties.
But even with all the amount of resources on SEO available on the web, and all the time I spend, I still couldn’t explain key aspects of what I saw to identify why certain keywords made us rank (or not). Up until I approached the problem from Google’s perspective… It all started making sense to me.
Google seemed to have quietly introduced a new approach to their ranking algorithm, and told nobody. Powered by their unprecedented computational and brain power, they finally were able to find a solution to deal with three key issues in the search ecosystem: web spam, fair rankings and stability.
This article is the first public disclosure of what I think is game changing fundamentally different SEO approach to interpreting the search rankings. I introduce to you: Domain Ranking Bandwidth (DRB) powered by a previously unidentified supervising Google algorithm.
None of the existing expert surveys mention a concept close to DRB. But it is able to explain much of the “why am I (not) ranking?” questions, haunting so many marketers, business owners, growth hackers and SEO experts.
Note: This write-up is still speculative. It is hard to get confirmation from Google on algorithm topics, but I am working on disclosing the data to my theory.
Please read on, and it will all start making sense:
Introduction
Search, the early days
A fundamental new approach
Introducing: Domain Ranking Bandwidth
Implications for ranking
In summary
Introduction
To understand the current state of search rankings, we’ll first have to take a step back to were Google search was coming from. This is fundamental in understanding why Google needed to change its approach to ranking in a big way and what it tried to solve.
Note: The timeline below is purely speculation.
Search, the early days (pre-2011)
mo searches, mo problems
Google was able to nail the ranking of websites for keywords early on in their existence. Their founders fundamental idea to use web links, as if they are citations had a proven track record in science for decades and worked perfectly well early on for the web.
The search and ranking nut seemed to be cracked. Google’s usage exploded. But with the success of their search engine, also came in the high-stakes. The traffic Google was sending, was worth real money. Big brands, local businesses, startups all the way down to web spammers — all getting addicted to the traffic, and all tried to boost their ranking.
Google’s reaction was to continuously adjust their algorithms to match the best quality results to searches. And changes they had to make. Many were rolled out, over many more years. Either focused on brands, promote diversity, quality content, localised results, fresh results, or plainly to weed out spam with (manual) penalties.
It was hard for Google to nail down the perfect mix. Especially in the ongoing battle with spam, they were up against tiresome spammers with little to lose.
But with all the algorithm changes to fix the SERP — besides different site rankings — their side-effects were hurting the company:
Bad PR. With every algorithm change, some mom-and-pop store got booted out of Google, leading to headlines of Google killing small businesses. Whatever the reason was, newspapers enjoyed writing about the narrative, and sites being penalised were actively pursuing the media so Google might undo their penalty. But also larger brands (BMW, JC Penny, Forbes) started demanding for Google to rank their sites and make a big stir when they weren’t. How could algorithm roll-outs (+ penalties) exists but maintain a stable SERP and not trigger negative PR?
Peak-Wikipedia. Certain properties — with as flagship example Wikipedia — had amassed so much authority and trust on a wide range of topics it was almost impossible not to see them rank in the top 3 slots for a search query. Especially commercial companies (Associated Content, Yahoo, Demand Media, etc.) saw their opportunity and used their authority to grab as much of traffic from Google by churning out content on any topic, and turned this into millions of ad revenue. A limited number of properties were too good, and took too much of the search traffic pie. How would the SERP continue to have enough variation and traffic spread more ‘fair’ over the web?
∞-Spam. Spamming the web had little to no costs. Literally. Weeding out one spammer, only made them move on and change tactics. Google’s compute & workforce would always be outnumbered in fighting the spammers because the spammer had only upside. How could Google increase the spammer costs?
Many more updates followed: Penguin, Panda, etc. All big thrives forward, but these didn’t solve the core issues Google faced with the search results: web spam, fair rankings and stability.
A fundamental new approach
precise and total control
By now — 2012 — Google became much more capable with a huge investment in compute power and workforce. For example it wasn’t serving a fixed set of results pages anymore for search keywords. The results became device-specific, localised, a/b-tested and personalised. Thousands of variations for a single keyword. Billions for keyword combinations.
Also Google had now the ability to continuously update it’s web index, go beyond just a top-10 by introducing specific one-box results, and roll-out changes with more granular controls and even disclosed many of them publicly.
To understand what happened next, let’s go back to the question on how to increase the spammers costs? Google’s web spam head Matt Cutts answer wants to start wasting the only limited resource available to the web spammers: time. Instead of kicking spamming domains out of the results, Google would from now on adjust the amount of traffic that would be allocated to the spammers domains on a downwards slope. Frustrating their efforts.
This resulted in spamming domains getting less and less total traffic over time. Not knowing they got flagged, slowly losing rankings overall.
While some individual ranking gains maintained to keep spammers wasting their time, the overall traffic was on a downward slope on its way to 0 in x amount of time.
Google had time and saw what it gained by not triggering the spammers attention after an algorithm change caught up with them. It would be frustrating and confusing the spammers, while wasting their time. Google’s great find.
This great find was then followed by a big EUREKA moment when Google’s engineers understood this could be applied to every website on the web.
With all the big data gathered from search, Google started taking precise and total control of all the traffic they sent out:
Google started allocating website domains a pre-defined search traffic bandwidth. All domain rankings in aggregate equal the total traffic allowed.
I call this the Domain Ranking Bandwidth (DRB). A supervising algorithm controlling all the traffic the search engine sends out to every domain. The algorithm allocates a pre-defined traffic bandwidth. The bandwidth consists of a lower and upper bounds allocated based on its authority and in which traffic is then assigned to you, through a specific position in the search results.
All individual domain rankings are together contributing to a pre-defined allocated bandwidth range.
The bandwidth behaves similar to how company stock price charts are analysed by analyst. To make future predictions on traffic (or price as with stock) an upper and lower bound is drawn in which the traffic fluctuates over time, but doesn’t break out. Every single ranking position of a domain translates to a certain amount of traffic, which in total falls within the domain's allocated bandwidth.
Google can predict the search volume for any keyword, the resulting traffic for each position, and for every variation of its search results.
Google's new algorithms are set to only adjust the angle of your domain ranking bandwidth over time.
One individual jump in rankings for a keyword caused by an underlying algorithm, will lead to more traffic, but if that causes the domain to break out of its upper bound, the supervising DRB algorithm will tweak other ranking positions a bit down, by applying a lower average positions to other keyword rankings, enough for the individual jump to keep the domain within bounds.
This strategy of allocating a bandwidth resolved the core search ranking issues Google faced :
Fairness.With every domain within its bandwidth, even Wikipedia, Yahoo! and Google itself, no single property could become all encompassing dominant. While an underlying algorithm might decide Wikipedia is the best to rank for a search query, the supervising DRB can determine Wikipedia is already at its upper bound in traffic, giving other websites the opportunity to take that position and traffic, or slightly adjust other Wikipedia rankings downwards.
Stability. No more big jumps leading to bad PR or frustrated webmasters. Search rankings have become boring and predicable(ish). Large e-commerce sites are able to predict their revenue (and invest it into Adwords ;)). The stability leads to an overall healthier ecosystem for Google, where everybody is incentivised to continue investing in (fresh) content over a longer period.
Spam. Spammers are identified and will head towards zero by adjusting only the slope of their bandwidth (strongly) downwards. Spammers continue to see rankings, but not knowing that their efforts are futile. The downside of this approach is that spam sites are still ranking sometimes, but slowly-and-steady they do disappear from the top results. With the spammer wasting their time on the thing they though (still) worked, instead of moving on to a new spam tactic.
Blackbox. As an extra, it makes it almost impossible to reserve engineer the rankings algorithm. Given many (sub-)optimal rankings , or shifts (+1 , -5) are based on the domain ranking bandwidth and not the site’s actions, content, linking, actions, etc. a single change has different outcomes. E.g. you could be doing amazing SEO wise, deserve lots of #1 positions, except for your bandwidth is fully filled, you are throttled by your upper bound. Then you can only just wait, until more and more rankings are slowly gained to match slowly increasing upper bound.
Implications for ranking
The domain ranking bandwidth has major implications for websites ranking in Google.
Chasing individual wins is futile if the overall DRB angle is flat (no growth). Obtaining individual ranking changes are not a tell-tale sign of you doing the right things, without taking into account your whole property’s DRB slope direction.
This is especially applies when you are already at the upper bound of the bandwidth:
A big win for a keyword you have been chasing, does not correlate to more total traffic. The DRB steps in, and the individual keyword win leads to an equal matching loss but masked by being spread over many other (average) rankings being dialed down.
Next to that, when dealing with rankings:
Charts. Daily charts lose their meaning. They miss the context of the long term direction.
Tracking. Individual keyword trackers are irrelevant.
Complexity. Decisions have to be made whether a win for one keyword, is worth the matching potential loss for others.
Wins. Seeing a #4 jump to #1 is fun but irrelevant, until it’s matched with an upwards slope of total traffic over a longer period.
Featured listing. A big win as a one-box as featured snippet, knowledge pain, “in the news” won’t scale for (all) other keywords, given it is merely a side-effect of you being chosen to fill the DRB’s needs.
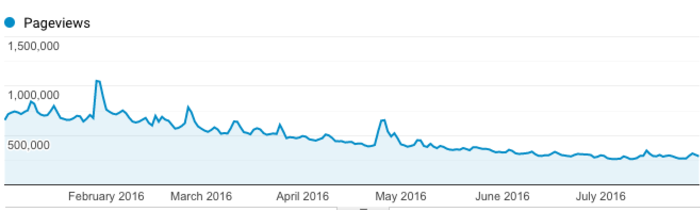
A real-life chart example is the property below. The organic traffic for a period of 8 months. The bandwidth slope is obviously downwards. Some rankings are gained but quickly throttled down to match the downwards slope (the peaks).
Variations occur on daily, weekly basis, but overall all ranking activity occurs within the DRB.
In summary:
Google allocates traffic to your domain using fine-grained control mechanisms.
Your website traffic from Google is bound to a pre-defined bandwidth (DRB).
The bandwidth only changes its slope slightly by your actions or new algorithm adjustments.
Google plays a long game, you need to align as well.
Stop interpreting a single keyword ranking, start using a broad holistic approach by looking at total traffic retrieved.
If you are at the upper bound of your DRB, any win equals a matching loss (spread over multiple rankings).
If you see lots of variation in traffic, good chance you have not reached your upper bound yet or you timeframe is set too small(< 14 days).
Continue to read part II (work in progress) which provides you a guide on how to identify your domain ranking bandwidth bounds, how to start thinking in long-term slope adjustments and help you read your existing rankings within this new framework and how to find a strategy to grow your traffic by interpreting the rankings within the DRB framework.
In the mean time follow me on Twitter @yvoschaap for when I post updates to uncover this topic further.
I am no way affiliated with Google Inc. and all statements are (educated) guesses.
The end of year again! Time for some semi-public reflection. First of all I've been neglecting my own blog, which for the record has been in this form since 2005 (and funnily enough started also with an end of year review). Which is kind of a waste given a blog is a great way to commit your thoughts.
I won't make any promises I might not keep, especially at a time of new years resolutions. But I want to share more here, and especially less based on me only checking in to promote some new launch (for which I've been abusing the blog now for a while). I like Seth's idea of just showing up which he re-iterates in his new book This is marketing (nice read). But I have not been doing that for a while...
I have mixed feelings for this year, but overal 2018 was a year with a good personal & professional focus (I think I know by now what makes me happy), but maybe not much luck with results (given my entrepreneurial KPIs are way 📉).
I launched Mailbook (which gets almost daily happy testimonials), my son went to school (and is very happy there), I totally enjoy development with React now, my daughter is potty trained at 2.5, and I launched several new projects under the build.amsterdam concept, and found a new (possible) partner along the way (hi Marco). And of course, our family enjoyed a healthy year (needs a mention when you pass the 25 I guess)
But the new year starts with a sad decision: I decided to stop operating Directlyrics (after over 11 years and 1 billion (!) page views). I've seen and enjoyed the high tide of lyrics, ringtones, licensing, ads and seo, but also the downsides of low value content, decreasing CPMs, increasing costs, and complexer competition. Read more in this IndieHacker post 👉.
I wasn't able to re-invent the project, didn't surprise users and stuck too long to SEO as acquisition strategy. But also to be fair, not from a lack of trying (lots of things were tried). In this case lyrics are a high traffic business and without the traffic (e.g. under 100k a day is unmaintainable) the revenue isn't enough to continue. Kevin (the editor) was amazing over the last decade. Hire him.
But this makes room for 2019 to let go of old habits, and start of fresh, finding new fuel and route to succes (defined as... ). Less lurking (bye Twitter), more actionable days (Hello OKRs) and even more focus (oops, this now does sound like a new years resolution).
I'll be enjoying the Swiss mountains the last few days. I'll keep you updated :)
Beginning this year (2018) me, Bram and Emiel decided to build a cool side project. Bram was then struggling with collecting addresses from friends to sent out an upcoming birth announcement, so he came up with the idea that we named Mailbook. After a user signs-up, he retrieves a personal link, shares that with his friends, friends add their address and the addresses appear neatly in their personal address book. Simple. And inherit viral, because every new user sends a link to Mailbook to on average over 50 other people (in the same demographic).
In 6 months over 40,000 people added their addresses to a Mailbook. Some users collected over 200 addresses in under two days. And growth only seems to accelerate. Very cool to see.
I continue to work on it, empowered by the positive feedback and incoming feature requests. Most recently I released a quick way to create and print address labels. Compare my solution with the horrors build by Word + Excel in this Dutch article adresetiketten printen.
But the latest change: an English version of Mailbook 🎉. Not only good for my Dutch users with international friends, but also to expand the reach of the product.