Google's supervising ranking algorithm theory
How Google created a supervising algorithm to precisely control all search traffic it sends out.
I’ve been spending the past 10 years watching, analysing and interpreting the search results on a daily basis. I’ve reviewed over 10 billion clicks from a Google search to one of my (clients-) web properties.
But even with all the amount of resources on SEO available on the web, and all the time I spend, I still couldn’t explain key aspects of what I saw to identify why certain keywords made us rank (or not). Up until I approached the problem from Google’s perspective… It all started making sense to me.
Google seemed to have quietly introduced a new approach to their ranking algorithm, and told nobody. Powered by their unprecedented computational and brain power, they finally were able to find a solution to deal with three key issues in the search ecosystem: web spam, fair rankings and stability.
This article is the first public disclosure of what I think is game changing fundamentally different SEO approach to interpreting the search rankings. I introduce to you: Domain Ranking Bandwidth (DRB) powered by a previously unidentified supervising Google algorithm.
None of the existing expert surveys mention a concept close to DRB. But it is able to explain much of the “why am I (not) ranking?” questions, haunting so many marketers, business owners, growth hackers and SEO experts.
Note: This write-up is still speculative. It is hard to get confirmation from Google on algorithm topics, but I am working on disclosing the data to my theory.
Please read on, and it will all start making sense:
- Introduction
- Search, the early days
- A fundamental new approach
- Introducing: Domain Ranking Bandwidth
- Implications for ranking
- In summary
Introduction
To understand the current state of search rankings, we’ll first have to take a step back to were Google search was coming from. This is fundamental in understanding why Google needed to change its approach to ranking in a big way and what it tried to solve.
Note: The timeline below is purely speculation.
Search, the early days (pre-2011)
mo searches, mo problems
Google was able to nail the ranking of websites for keywords early on in their existence. Their founders fundamental idea to use web links, as if they are citations had a proven track record in science for decades and worked perfectly well early on for the web.
The search and ranking nut seemed to be cracked. Google’s usage exploded. But with the success of their search engine, also came in the high-stakes. The traffic Google was sending, was worth real money. Big brands, local businesses, startups all the way down to web spammers — all getting addicted to the traffic, and all tried to boost their ranking.
Google’s reaction was to continuously adjust their algorithms to match the best quality results to searches. And changes they had to make. Many were rolled out, over many more years. Either focused on brands, promote diversity, quality content, localised results, fresh results, or plainly to weed out spam with (manual) penalties.
It was hard for Google to nail down the perfect mix. Especially in the ongoing battle with spam, they were up against tiresome spammers with little to lose.
But with all the algorithm changes to fix the SERP — besides different site rankings — their side-effects were hurting the company:
-
Bad PR. With every algorithm change, some mom-and-pop store got booted out of Google, leading to headlines of Google killing small businesses. Whatever the reason was, newspapers enjoyed writing about the narrative, and sites being penalised were actively pursuing the media so Google might undo their penalty. But also larger brands (BMW, JC Penny, Forbes) started demanding for Google to rank their sites and make a big stir when they weren’t.
How could algorithm roll-outs (+ penalties) exists but maintain a stable SERP and not trigger negative PR? -
Peak-Wikipedia. Certain properties — with as flagship example Wikipedia — had amassed so much authority and trust on a wide range of topics it was almost impossible not to see them rank in the top 3 slots for a search query. Especially commercial companies (Associated Content, Yahoo, Demand Media, etc.) saw their opportunity and used their authority to grab as much of traffic from Google by churning out content on any topic, and turned this into millions of ad revenue. A limited number of properties were too good, and took too much of the search traffic pie.
How would the SERP continue to have enough variation and traffic spread more ‘fair’ over the web? - ∞-Spam. Spamming the web had little to no costs. Literally. Weeding out one spammer, only made them move on and change tactics. Google’s compute & workforce would always be outnumbered in fighting the spammers because the spammer had only upside.
How could Google increase the spammer costs?
Many more updates followed: Penguin, Panda, etc. All big thrives forward, but these didn’t solve the core issues Google faced with the search results: web spam, fair rankings and stability.
A fundamental new approach
precise and total control
By now — 2012 — Google became much more capable with a huge investment in compute power and workforce. For example it wasn’t serving a fixed set of results pages anymore for search keywords. The results became device-specific, localised, a/b-tested and personalised. Thousands of variations for a single keyword. Billions for keyword combinations.
Also Google had now the ability to continuously update it’s web index, go beyond just a top-10 by introducing specific one-box results, and roll-out changes with more granular controls and even disclosed many of them publicly.
To understand what happened next, let’s go back to the question on how to increase the spammers costs? Google’s web spam head Matt Cutts answer wants to start wasting the only limited resource available to the web spammers: time. Instead of kicking spamming domains out of the results, Google would from now on adjust the amount of traffic that would be allocated to the spammers domains on a downwards slope. Frustrating their efforts.
This resulted in spamming domains getting less and less total traffic over time. Not knowing they got flagged, slowly losing rankings overall.
While some individual ranking gains maintained to keep spammers wasting their time, the overall traffic was on a downward slope on its way to 0 in x amount of time.
Google had time and saw what it gained by not triggering the spammers attention after an algorithm change caught up with them. It would be frustrating and confusing the spammers, while wasting their time. Google’s great find.
This great find was then followed by a big EUREKA moment when Google’s engineers understood this could be applied to every website on the web.
With all the big data gathered from search, Google started taking precise and total control of all the traffic they sent out:
Google started allocating website domains a pre-defined search traffic bandwidth. All domain rankings in aggregate equal the total traffic allowed.
I call this the Domain Ranking Bandwidth (DRB). A supervising algorithm controlling all the traffic the search engine sends out to every domain. The algorithm allocates a pre-defined traffic bandwidth. The bandwidth consists of a lower and upper bounds allocated based on its authority and in which traffic is then assigned to you, through a specific position in the search results.

All individual domain rankings are together contributing to a pre-defined allocated bandwidth range.
The bandwidth behaves similar to how company stock price charts are analysed by analyst. To make future predictions on traffic (or price as with stock) an upper and lower bound is drawn in which the traffic fluctuates over time, but doesn’t break out. Every single ranking position of a domain translates to a certain amount of traffic, which in total falls within the domain's allocated bandwidth.
Google can predict the search volume for any keyword, the resulting traffic for each position, and for every variation of its search results.
Google's new algorithms are set to only adjust the angle of your domain ranking bandwidth over time.

One individual jump in rankings for a keyword caused by an underlying algorithm, will lead to more traffic, but if that causes the domain to break out of its upper bound, the supervising DRB algorithm will tweak other ranking positions a bit down, by applying a lower average positions to other keyword rankings, enough for the individual jump to keep the domain within bounds.
This strategy of allocating a bandwidth resolved the core search ranking issues Google faced :
- Fairness.With every domain within its bandwidth, even Wikipedia, Yahoo! and Google itself, no single property could become all encompassing dominant. While an underlying algorithm might decide Wikipedia is the best to rank for a search query, the supervising DRB can determine Wikipedia is already at its upper bound in traffic, giving other websites the opportunity to take that position and traffic, or slightly adjust other Wikipedia rankings downwards.
- Stability. No more big jumps leading to bad PR or frustrated webmasters. Search rankings have become boring and predicable(ish). Large e-commerce sites are able to predict their revenue (and invest it into Adwords ;)). The stability leads to an overall healthier ecosystem for Google, where everybody is incentivised to continue investing in (fresh) content over a longer period.
- Spam. Spammers are identified and will head towards zero by adjusting only the slope of their bandwidth (strongly) downwards. Spammers continue to see rankings, but not knowing that their efforts are futile. The downside of this approach is that spam sites are still ranking sometimes, but slowly-and-steady they do disappear from the top results. With the spammer wasting their time on the thing they though (still) worked, instead of moving on to a new spam tactic.
- Blackbox. As an extra, it makes it almost impossible to reserve engineer the rankings algorithm. Given many (sub-)optimal rankings , or shifts (+1 , -5) are based on the domain ranking bandwidth and not the site’s actions, content, linking, actions, etc. a single change has different outcomes. E.g. you could be doing amazing SEO wise, deserve lots of #1 positions, except for your bandwidth is fully filled, you are throttled by your upper bound. Then you can only just wait, until more and more rankings are slowly gained to match slowly increasing upper bound.
Implications for ranking
The domain ranking bandwidth has major implications for websites ranking in Google.
Chasing individual wins is futile if the overall DRB angle is flat (no growth). Obtaining individual ranking changes are not a tell-tale sign of you doing the right things, without taking into account your whole property’s DRB slope direction.
This is especially applies when you are already at the upper bound of the bandwidth:
A big win for a keyword you have been chasing, does not correlate to more total traffic. The DRB steps in, and the individual keyword win leads to an equal matching loss but masked by being spread over many other (average) rankings being dialed down.
Next to that, when dealing with rankings:
- Charts. Daily charts lose their meaning. They miss the context of the long term direction.
- Tracking. Individual keyword trackers are irrelevant.
- Complexity. Decisions have to be made whether a win for one keyword, is worth the matching potential loss for others.
- Wins. Seeing a #4 jump to #1 is fun but irrelevant, until it’s matched with an upwards slope of total traffic over a longer period.
- Featured listing. A big win as a one-box as featured snippet, knowledge pain, “in the news” won’t scale for (all) other keywords, given it is merely a side-effect of you being chosen to fill the DRB’s needs.
A real-life chart example is the property below. The organic traffic for a period of 8 months. The bandwidth slope is obviously downwards. Some rankings are gained but quickly throttled down to match the downwards slope (the peaks).
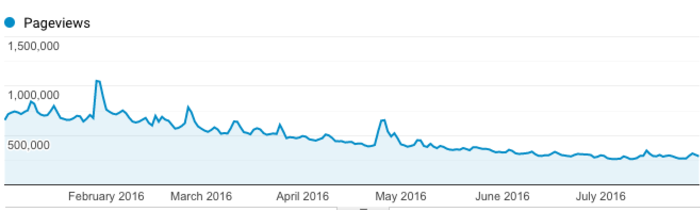
Variations occur on daily, weekly basis, but overall all ranking activity occurs within the DRB.
In summary:
- Google allocates traffic to your domain using fine-grained control mechanisms.
- Your website traffic from Google is bound to a pre-defined bandwidth (DRB).
- The bandwidth only changes its slope slightly by your actions or new algorithm adjustments.
- Google plays a long game, you need to align as well.
- Stop interpreting a single keyword ranking, start using a broad holistic approach by looking at total traffic retrieved.
- If you are at the upper bound of your DRB, any win equals a matching loss (spread over multiple rankings).
- If you see lots of variation in traffic, good chance you have not reached your upper bound yet or you timeframe is set too small(< 14 days).
Continue to read part II (work in progress) which provides you a guide on how to identify your domain ranking bandwidth bounds, how to start thinking in long-term slope adjustments and help you read your existing rankings within this new framework and how to find a strategy to grow your traffic by interpreting the rankings within the DRB framework.
In the mean time follow me on Twitter @yvoschaap for when I post updates to uncover this topic further.
I am no way affiliated with Google Inc. and all statements are (educated) guesses.

